
Diving into the World of GANs
Generative Adversarial Networks (GANs) are known for their success in generating realistic data. This ability has far-reaching implications across industries from entertainment to healthcare, art, and beyond. GANs have been used to create lifelike images, generate novel text, compose music, and assist in drug discovery. They were introduced in 2014 by Ian Goodfellow and his colleagues and have certainly found their way into popular culture.
Let’s unpack this terminology: Generative Adversarial Networks. They are generative in that they create something. As mentioned above, GANs have been used to create a variety of things. They are adversarial in that they rely on a competition between their components.

In order to understand GANs the diagram above helps us identify the fundamental building block of an (artificial) neural network: the perceptron. A perceptron is a node, which we can think of as a little bit of math modeled after the human brain. It takes in a bunch of numbers, called a vector, performs a computation, then outputs a number. You might have heard folks talking about parameters, weights, biases, activation functions—these are the mathematical bits of this model.
GANs contain two groups of perceptrons. Each of these groups is called a “neural network.” A single network will have tens, hundreds, or thousands of perceptrons, or even more, which are organized into layers. There is an input layer, an output layer, and some number of layers between them. This layering is what makes neural networks “deep.” Each layer of perceptrons takes in the output from the previous layer, processes it, and passes it to the next layer. The final layer, the output, generates something called a prediction. This prediction is the thing that the user from the network desired such as the prediction of a stock price or a cat photo no one has seen before.
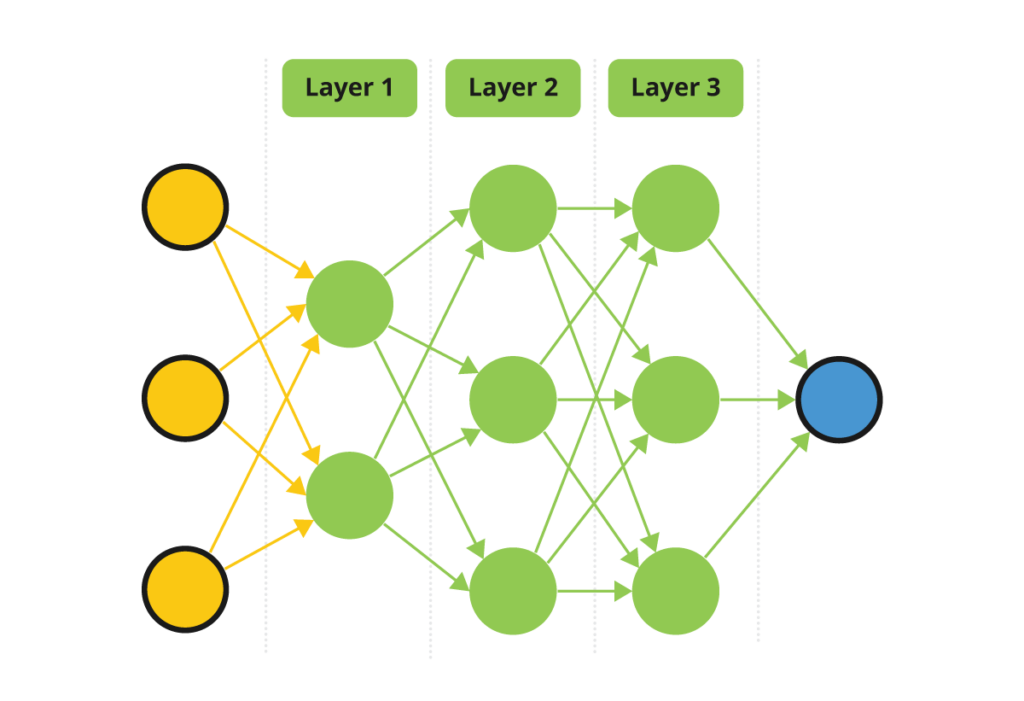
See the figure below for how these networks are arranged to form a GAN. Each colored circle is a perceptron. The perceptrons are arranged in layers. The input vector starts at the left of each network and is processed by the perceptrons in each layer before passing to the next layer, then finally the output. In the case of the generator, the output is an image. These generated images are in a sense novel and are influenced by the data that was used to train the other network in the architecture: the discriminator.
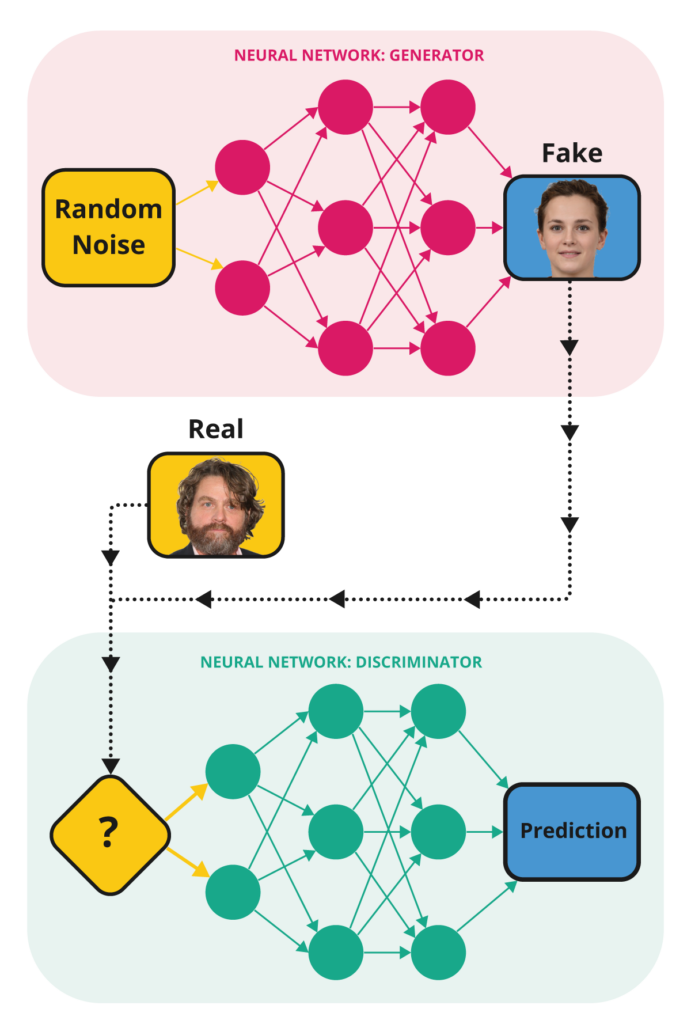
This is an example of an architecture for a generative adversarial network. Notice the two neural networks: the generator and the discriminator.
An input into a generative network could be numbers, text, or an image, for example. This input is first transformed into a list of numbers called a vector. Each perceptron in the neural network performs a computation on the input vector, then passes its output into another vector which is then input into other perceptrons in the network until an output is produced. This vector is then transformed back into the desired output: text, image, etc.
That final output, again, is called a prediction. This prediction could be used to tell us whether or not an image of a painting is fake. It could also be the next word in a text message, or a recommendation for a movie to watch. The prediction depends on what the model was designed and trained to do.
You might be wondering, “How does the neural network know the values of these parameters in each perceptron?” When the neural network is first created, the parameters are unknown. They have to be learned through a process called training. Training is accomplished through trial-and-error. During training, the network intelligently tries different values for the parameters until (hopefully) converging on parameter values that produce accurate predictions. Don’t expect the neural network to always produce accurate predictions. Training a neural network to produce accurate results is a lengthy topic and we won’t go into more detail here.
We have covered Generative and Neural Networks, but where does “adversarial” come into play? Let’s consider a thought experiment to help us understand.
Suppose that you wanted to train a neural network to spot, or discriminate, fake art. What would you do? You could take a neural network and train it against images of real art work such as the Mona Lisa, Persistence of Memory, and Water Lilies, etc. You are also going to need examples of fake artwork. Suppose for now, that you had a technique for creating them. You then train the model on fake and real art work. When the training is finished, you will have a model that can discriminate whether an image of art is real or fake. That is, this “discriminator” can take in an image of some art and tell you whether or not it is fake
That’s great, but how are we going to generate the fakes in order to train the discriminator? One way of doing that would be to create another neural network. Let’s call this a generator. The generator would be trained to generate fake artwork. How would this be accomplished?
It turns out that you can train both models simultaneously. You connect the output of the generator to the discriminator, so that you can feed the discriminator real and fake images. You then connect the output of the discriminator to the generator so that the generator can train while the discriminator is trained. In this way, as the discriminator learns to spot fakes, the generator gets increasingly good at generating fakes.
During training we have two networks attempting to trick each other. The generator tries to trick the discriminator into thinking that its images are real, whereas the discriminator tries to predict accurately which images are real and which are fakes. This gives rise to the adversarial nature of this technique.
“Only in the friction of conflict does the light of truth shine.”
John Stuart Mill
After training is complete, the generator can be used to generate images, or whatever media it was trained on. Image generation using this technique is limited by the corpus of training material. The generator in the previous example can be used to create images of real looking, but fake art work in the style of the input art. If instead you wanted to create novel human faces, you would need to train a GAN using images of human faces.
Similarly, any biases present in the training data would also be present in the predictions from the network. For example, if a GAN were trained on images of purple bunnies, the network would learn that all bunnies are purple. In a sense, the network only knows of purple bunnies because it was trained to generate images from images of only purple bunnies. Thus, neural networks are constrained by a form of tunnel vision because their predictions are limited by whatever constraints or biases are present in the training data.
In another sense, the above paragraph about a neural network learning to think that all bunnies are purple is rubbish. In fact, the network has no concept of purple or bunny or of images for that matter. All the network knows is to process input numbers according to the (mathematical) rules that it learned during training. It just so happens that the rules that it learned can only produce a series of numbers that when rendered a certain way, a human looking at it will see a construct that a reasonable English-speaking person would recognize as a purple bunny.
GANs, and other types of networks, have run into a bit of controversy. This has to do with copyright around the ownership of the training material. There are tools being created to prevent this.
AI’s Creative Frontier: The Endless Possibilities of GANs
In conclusion, GANs use two neural networks: one trained to spot fakes, and the other trained to generate fakes. In this way, the generator can be used in isolation to create fakes. While a very lengthy topic, we briefly discussed neural networks and how they work. Check back in the future as we post more on the topic of neural networks and machine learning!

