
Context is Everything
ChatGPT, and more generally, Large Language Models (LLMs), represent the state-of-the-art in generative text technologies. They are already shaping how professionals and content creators perform their work. From here out, I will stop referring to ChatGPT specifically. Although what I say applies, I will use the more general label of LLMs when referring to large language models, i.e. text generation. As we delve further, we’ll discuss the use of Retrieval Augmented Generation (RAG), a method used to address some of the context limitations of LLMs.
The Limits of Large Language Models
LLMs have no knowledge of anything outside of the material that they were trained on. How many times has ChatGPT responded to you that it knows nothing about what happened after September 2021? Wouldn’t it be great to supply your own source of data external to ChatGPT to be able to query that through a chat-like interface?
Or maybe you had a conversation with an LLM and it inserted a new idea seemingly of its own? I was once working on some software that was interfacing with a database. It was one of my initial close encounters with coding alongside an LLM. Not knowing what to expect I was surprised when it began to drift off course.
I was working on a Node.js Express application that used MongoDB. We were not using Mongoose or another Object Relational Mapping (ORM). We were interfacing with MongoDB directly through its client. The LLM was happily giving me JavaScript all afternoon, when all of a sudden it switched to giving me MongoDB shell commands instead of commands through the client in JavaScript. At the time, I was shocked and it took some time for me to realize what it was doing.
In retrospect, I believe what happened is that it did not apply the right context to the problem. For some reason, when I asked it to send me commands for Mongo, it “forgot” about the JavaScript context. MongoDB shell commands are a fine way to perform maintenance on the db, but were not what I was looking for as part of building a functional web application. So, how did the JavaScript context get lost?
The Problems with Context in LLMs
When you ask a question to an LLM, you are not only sending the query, you are also sending context. The context is typically the last few exchanges of dialog in the conversation. Let’s call this, the last “n” chats. The query and the context is usually enough for the LLM to be able to compose an accurate or at least confident and compelling response. There are limits though.
Depending on the model, you can only send ones or tens of thousands of words. That might sound like a lot, but this does put an upper limit on the length of the conversation history that an LLM can “remember”. This limit explains why it might switch context from MongoDB JavaScript client conversation to a MongoDB shell command conversion seemingly without warning: JavaScript was no longer in the conversation history, i.e the context.
Solving the Context Problem: Semantic Search
It is clear that we need to make the most use of the (limited) context that we have. But how do we do that? Semantic search. In order to understand semantic search, let us first explore another type of search, keyword search:
- In keyword searches, keywords are presented to a data storage system.
- Querying is accomplished by looking at the overlap between the key words supplied in the query versus others appearing in storage as text.
- Semantic search queries instead rely on context, concepts, and meaning in the query.
For example, consider searching for the word Java. A keyword search could include content about the programming language, the island, and the coffee. On the other hand, semantic search considers the context around and in the query. If the context contains java and beverage, then coffee would return. Whereas, java and code would return information about the programming language.
How is Semantic Search Accomplished?
LLMs rely on something called embeddings in order to encode meaning and more efficiently work across large groups of text. These embeddings are vectors in some highly dimensional vector space: ChatGPT uses vectors of length 1536. It turns out that these vectors cluster in proximity to other vectors that are semantically similar. Similarly, when a vector database is queried, the database returns vectors, i.e. embeddings, of other text that are in close proximity to the input vector. These embeddings are then transformed back into text. This is semantic search.
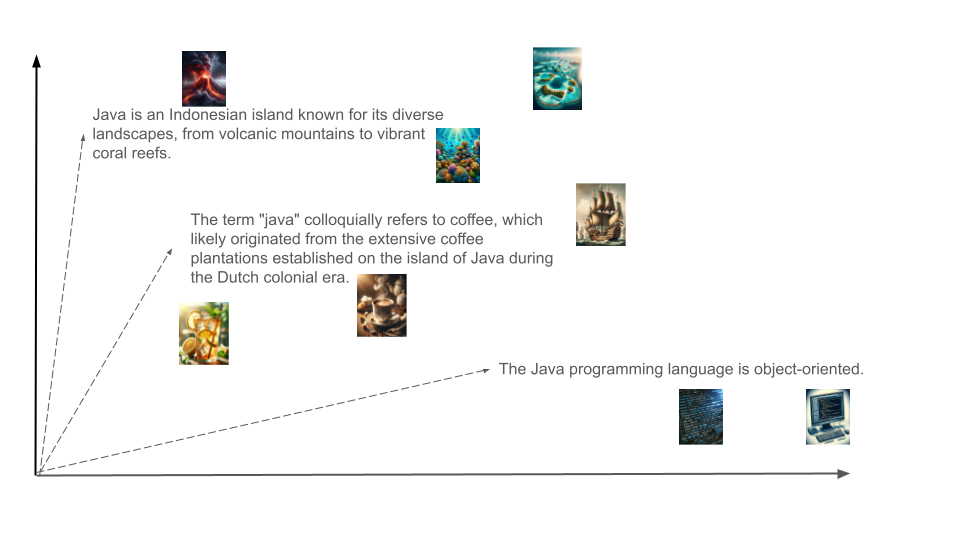
This text from the vector database can then be used as the context to be sent to ChatGPT. Making efficient use of the context is critical. By querying a vector database, we help to ensure that the context sent to the LLM is relevant. This process of using a vector database to supply context for an LLM is called Retrieval Augmented Generation (RAG).
Empowering Innovation with Retrieval Augmented Generation
By using Retrieval Augmented Generation, we can improve the effectiveness of LLMs. Retrieval augmented generation (RAG) allows searching data outside the material the model was trained on. In this way, we can improve the chances that the LLM will return relevant information. Recall from above that vector databases work via semantic search. In this way, embedding your queries and sending those vectors to the database as ‘queries” allows you to converse with your data in much the same way that you can chat with an LLM.

